它的作者 liliMozi 是一位中国开发者,一人全职维护这个项目——从代码到设计到文档,一个人扛下了整个产品。这篇文章基于实际使用体验,聊聊这个项目的定位、核心机制、和同类产品的差异。
![]()
一、先说定位
OpenHanako 的核心卖点不是“比 Claude Code 更强”或“比 Manus 更自动”。它试图回答一个不同的问题:AI Agent 能不能像一个靠谱的同事一样,长期驻留在你的工作环境里?
放一张表看它和主流 Agent 的定位差异:
| 类型 | 代表 | 交互方式 | 目标用户 | 核心价值 |
|---|---|---|---|---|
| IDE Copilot | Cursor / Cline | 嵌入编辑器 | 开发者 | 代码补全 |
| CLI Agent | Claude Code / Codex | 终端命令行 | 开发者 | 任务执行 |
| 通用对话 | ChatGPT / Claude Desktop | 网页/App | 所有人 | 单次问答 |
| 桌面常驻 Agent | OpenHanako | 桌面 GUI + 多平台 | 所有人 | 长期陪伴 + 主动行动 |
OpenHanako 的作者在 README 里写得很直白:“我本职也是一介文员,所以我也针对日常办公场景做了很多工具性和流程性的优化。” 这句话解释了它和 CLI-first 的 Agent 们为什么长得不一样——它从一开始就是为“不写代码的人”设计的。
二、记忆系统:不是 RAG,是“时间的重量”
大部分 Agent 的记忆方案是向量数据库 + RAG:把对话 embed 进去,检索时按相似度捞。OpenHanako 用的是一套时间衰减记忆模型:
- 近期事件:高精度保留,细节清晰
- 中期记忆:自动压缩编译,保留关键事实
- 长期记忆:LLM 周期性编译,沉淀为结构化事实
这个设计的好处是“记忆有轻重缓急”。你昨天随口说的“明天要交报告”,Agent 记得清清楚楚;但三个月前的一次闲聊,它只保留核心结论,不会把每个细节都塞进上下文窗口浪费 token。
实际体验下来,记忆编译的质量取决于底层模型。用强模型(GPT-4o / Claude Sonnet)编译出来的记忆更准确,用小模型偶尔会丢失细节或产生幻觉。这是所有记忆系统的通病,不是 OpenHanako 独有的问题。
三、人格系统:每个 Agent 都是“一个人”
OpenHanako 的人格不是简单的 system prompt 加个名字。它有一套完整的人格模板 + 行为逻辑机制:
- SOUL.md:定义 Agent 的核心性格、说话方式、价值观
- 人格模板:预置多种风格(温柔、理性、幽默……),也可以自由创作
- 行为逻辑:不只是“怎么说”,还影响“怎么做”——主动关心你的情绪、在合适的时候提醒你休息
这点在实际使用中感受很明显。传统 Agent 你问它答,你不问它就沉默。OpenHanako 的 Agent 会根据上下文主动发起对话——比如你连续工作三小时没休息,它可能会提醒你该起来活动了。
当然,这种“主动性”也需要调校。太主动会烦人,太被动又失去意义。作者在安全模型上做了平衡:主动行为需要通过审核,不会随便乱发消息。
四、多 Agent 协作:不只是一个助手,是一个团队
OpenHanako 支持创建多个 Agent,各自有独立的记忆、人格和技能。Agent 之间可以通过两种方式协作:
- 频道群聊:多个 Agent 在同一个频道里讨论问题,类似 Slack 的群组
- 任务委派:主 Agent 可以把子任务分配给其他 Agent,各自独立执行
这个设计让“分工”成为可能。比如你可以有一个专门负责写作的 Agent、一个负责数据分析的 Agent、一个负责日程管理的 Agent,它们各自擅长自己的领域,遇到跨领域问题时互相请教。
实际使用中,多 Agent 的协调成本不低——Agent 之间的对话可能会跑偏,需要人工干预。但这个方向是对的:单个 Agent 的能力有天花板,协作才能突破。
五、工具与技能:不只是调 API
OpenHanako 的工具覆盖了日常办公的绝大多数场景:
| 工具类别 | 具体能力 |
|---|---|
| 文件操作 | 读写文件、浏览文件树、拖拽上传 |
| 终端 | 一次性命令、持续终端会话 |
| 浏览器 | 网页导航、截图、长截图、元素检查 |
| 媒体 | 图片/视频预览、SVG 查看、全屏查看器 |
| 网络 | 搜索引擎、网页抓取、API 调用 |
| 日程 | 定时任务(Cron)、心跳巡检 |
更值得关注的是技能系统。OpenHanako 兼容 Skills 社区生态,但做了一个有意思的优化:Agent 可以自己学习新技能。当它成功完成一个任务后,会自动把流程沉淀为可复用的技能文档,下次遇到类似任务直接调用。
这和 Hermes Agent 的“自我进化”理念相似,但 OpenHanako 的实现更偏向“人工审核 + 自动沉淀”的混合模式——技能需要通过安全审核才能正式启用,避免了“自动学习出错误技能”的风险。
Vision Bridge:让文本模型“看见”世界
有一个容易被忽略但非常聪明的设计:Vision Bridge。
DeepSeek V4 是一个纯文本模型(多模态版本据称已在测试中,但截至本文写作时尚未正式发布),本身不具备理解图片的能力。OpenHanako 的做法不是等模型升级,而是在架构层面做了一个适配层——当你向 Agent 发送图片时,系统自动调用一个独立配置的视觉模型(可以是 GPT-4o、Claude 等任意支持多模态的模型)来“翻译”图片内容为文字描述,再把这段描述作为上下文注入到对话中。对文本模型来说,它看到的就是一段“用户发了一张图,图里是什么”的自然语言描述,而不需要理解图片本身。
这个设计的巧劲在于不改造模型,只改造输入:
- 用户端无感。你直接拖图进去,Agent 就能“看懂”,不需要任何额外操作
- 成本可控。视觉模型只被调用一次做图片翻译,后续多轮对话仍由廉价的文本模型处理,对 DeepSeek V4 这种低价模型的生态来说尤其适配
- 模型无关。Vision Bridge 的视觉模型可以在设置页单独选择更换,不和对话模型绑定
说实话,这种“用工程手段弥合模型能力边界”的思路,比等着模型厂商发新版本务实得多。作者用几行适配代码解决了一个“文本模型就是文本模型”的硬限制,而且解得漂亮。她在抖音也分享过对 DeepSeek 的深度适配经验,感兴趣的可以看看:我给 DeepSeek 做了一套专属武装。
六、安全沙盒:给 AI 划红线
Agent 能操作你的电脑,安全问题就是头等大事。OpenHanako 的安全设计是双层隔离:
第一层:应用级 PathGuard(四级访问控制)
- 只读访问系统普通文件
- 写入和删除限制在工作目录与受控数据目录
- 敏感操作需要用户确认
第二层:操作系统级沙盒
- macOS:Seatbelt
- Linux:Bubblewrap
- Windows:restricted token
这意味着即使 Agent 的指令有误,它也无法突破沙盒去删除系统文件或访问不该访问的目录。在设置里还可以调整沙盒级别——从“严格”到“宽松”,根据你的信任程度选择。
七、多平台接入:同一个 Agent,随处对话
OpenHanako 通过 Bridge 机制,让同一个 Agent 可以同时接入:
- Telegram
- 飞书
- 微信
- CLI(终端)
你在电脑前和 Agent 对话,出门后用手机上的微信继续同一个话题,Agent 的记忆是连续的。这对“跨设备工作流”来说是刚需。
更实用的是移动端 PWA:通过手机访问 Hana Server,可以查看会话、继续聊天、管理工作台文件。不需要额外装 App,浏览器打开就能用。
八、技术架构速览
| 层级 | 技术 |
|---|---|
| 桌面端 | Electron 38 |
| 前端 | React 19 + Zustand 5 + CSS Modules |
| 构建 | Vite 7 |
| 服务端 | Hono + @hono/node-server |
| Agent 运行时 | Pi SDK |
| 数据库 | better-sqlite3(WAL 模式) |
| 测试 | Vitest |
| 国际化 | 5 语言(中/英/日/韩/繁体) |
Server 以独立 Node.js 进程运行(由 Electron spawn 或独立启动),与 Electron 渲染进程通过 WebSocket 通信。用户数据目录默认在 ~/.hanako,每个 Agent 是一个独立的文件夹,备份和迁移都很方便。
九、和同类产品对比
| 维度 | OpenHanako | Hermes Agent | OpenClaw | Claude Desktop |
|---|---|---|---|---|
| 界面 | 桌面 GUI + 移动 PWA | CLI + Telegram | 桌面 GUI | 桌面 App |
| 目标用户 | 所有人 | 开发者 | 开发者 | 所有人 |
| 记忆方案 | 时间衰减 + LLM 编译 | FTS5 + Honcho | 显式记忆 | 会话内 |
| 技能来源 | 自动沉淀 + 人工审核 | 自动生成 | 人工编写 | 插件市场 |
| 沙盒 | PathGuard + OS 级 | 用户授权 | 文件级身份 | 受限 |
| 模型支持 | OpenAI / Anthropic / Ollama 等 | 模型无关 | 模型无关 | 仅 Claude |
| 多 Agent | 支持(频道 + 委派) | 支持(子 Agent) | 不支持 | 不支持 |
| 多平台 | Telegram/飞书/QQ/微信 | Telegram/Discord/Slack/WhatsApp | 无 | 无 |
| 开源 | Apache 2.0 | Apache 2.0 | 开源 | 闭源 |
简单说:Hermes 适合想“放养”型自学习的开发者,OpenClaw 适合想“圈养”型可控助手的开发者,OpenHanako 适合想要“有温度的长期伙伴”的所有人。
十、审美本身就是功能
聊完功能和技术,必须单独说一句视觉设计。这不是那种“界面好看就行”的凑字数段落——对 OpenHanako 来说,审美是功能性的。
一个软件如果长得丑,你永远不会和它建立情感连接。CLI 可以丑,因为终端的美学是效率;但一个自称“有温度的长期伙伴”的东西如果界面刺眼、排版混乱、配色廉价,它说自己有灵魂你是不会信的。OpenHanako 在这一点上做得很清醒。
配色与暗色模式
不是那种程序员自嗨的高饱和度赛博朋克风,也不是大厂 ToB 软件那种灰蒙蒙的“性冷淡”。OpenHanako 的配色偏向暖灰色调,大面积留白,重点色克制地用在交互焦点上,整体观感接近一款做得好的日系笔记 App。暗色模式不是简单的黑底白字——深色背景有微妙的暖灰渐变,文字层级清晰但不刺眼,长时间盯着窗口不会疲劳。
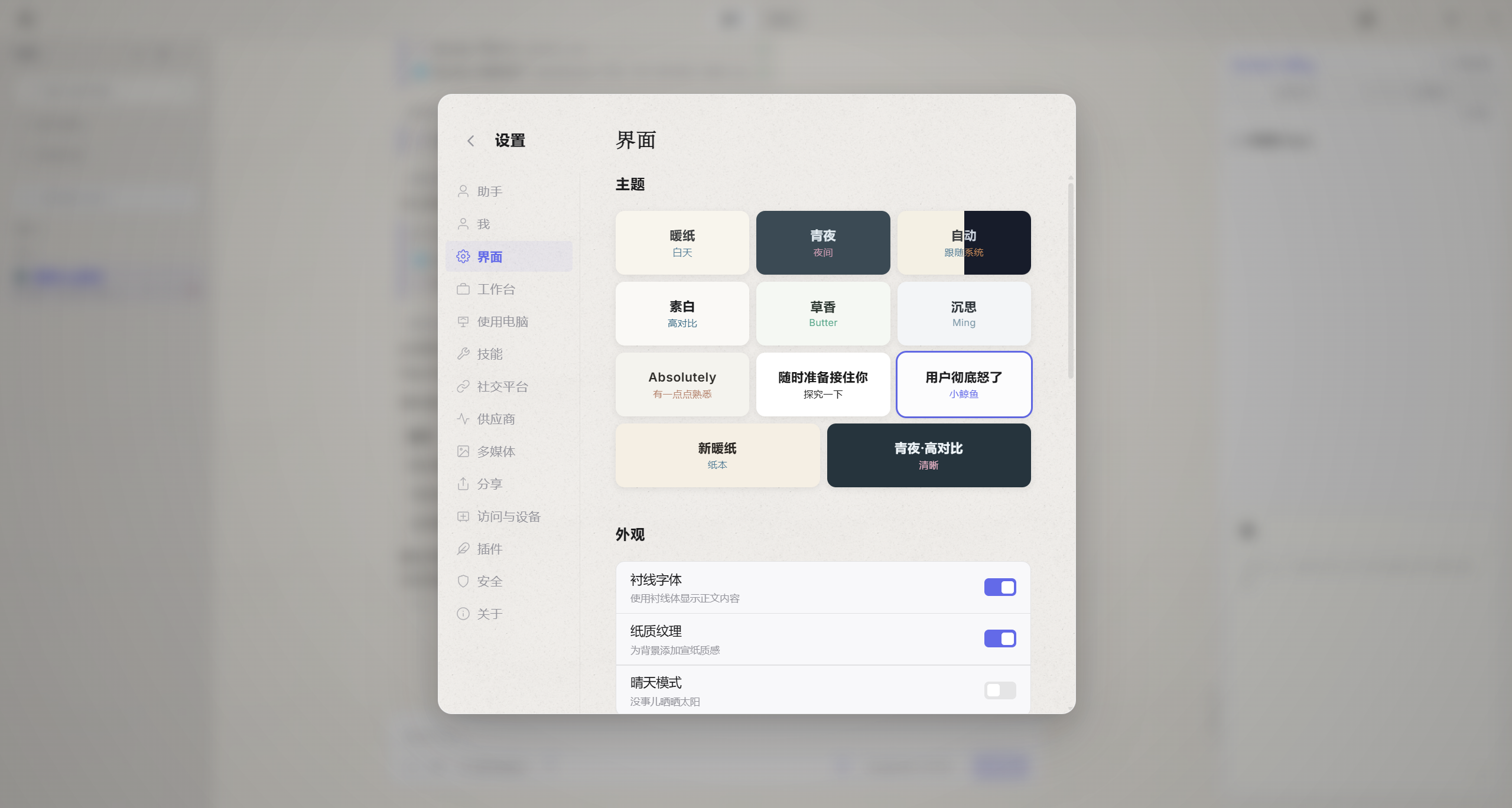
光是主题名字就能看出作者的审美自觉:暖纸、青夜、草香、沉思、素白——每个名字不是功能描述,而是一种情绪提示。你选的不是“深色背景”,你选的是“今晚想待在一个青色的夜里”。暗色模式可以叫高对比,但它偏叫“青夜·高对比”。这些命名背后有一个罕见的意识:界面的每一个字都在和用户对话,而 OpenHanako 选择说人话。
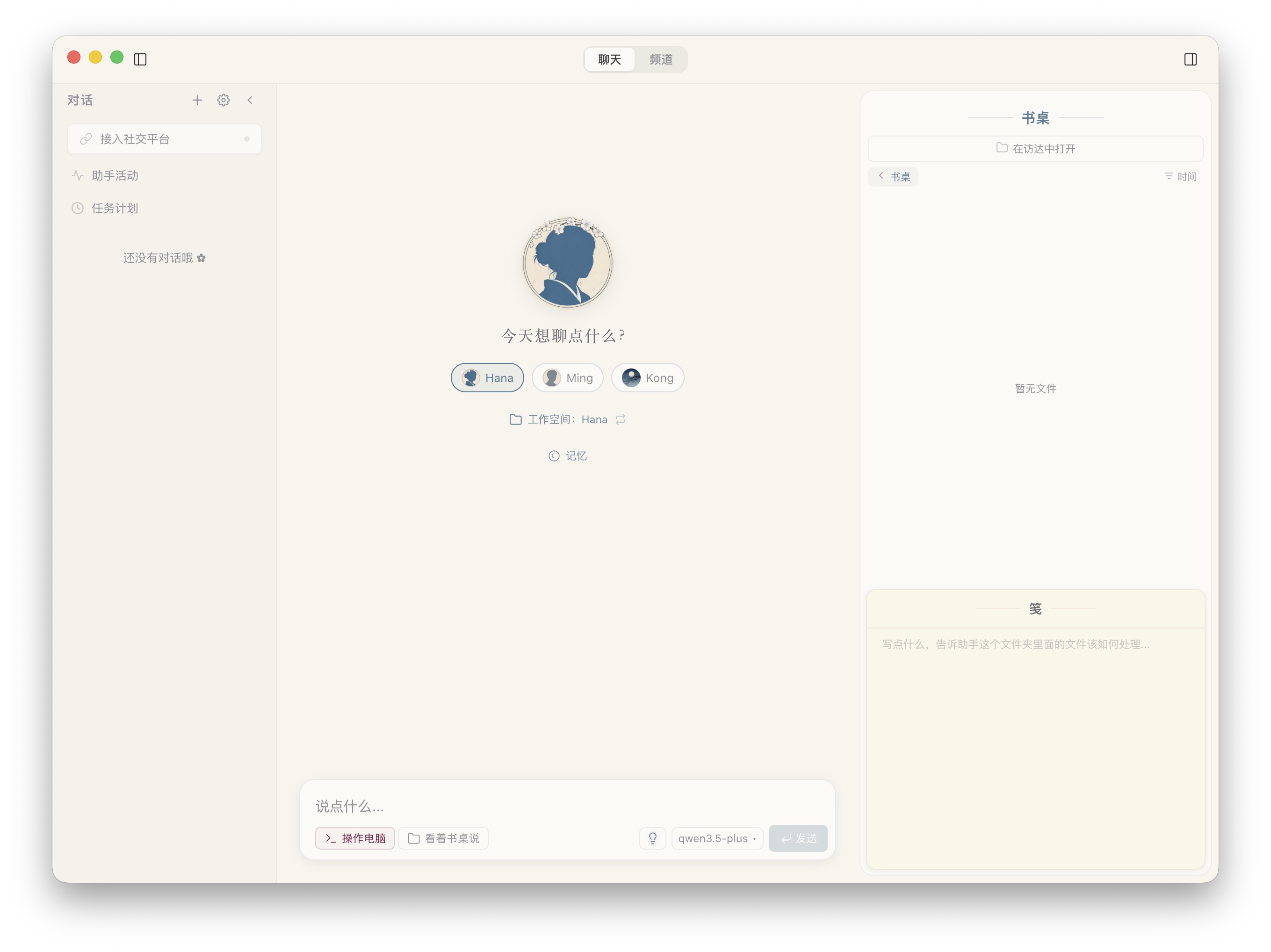
书桌:拟物而不俗气
每个 Agent 都有自己的书桌,可以在上面放文件、写笺(类似便签)。这个设计巧在两点:
- 空间隐喻做得很自然。你和 Agent 共享一张虚拟桌面,而不是一个聊天框。拖拽文件到书桌上,Agent 会感知到变化并主动读取——这个交互把“我给 AI 塞了个文件”翻译成了“我往桌上放了张纸条”,不需要学习任何新概念。
- 拟物但不土。很多国内软件的拟物设计要么过度(阴影到处都是、材质贴图堆满),要么生搬 iOS 那套磨砂玻璃。OpenHanako 的书桌保留了拟物的直觉(“这是桌子”),但视觉上做了扁平化处理——阴影只起到层级提示的作用,不抢注意力。
全屏媒体查看器:细节里的功力
这是个小功能,但能看出作者的审美直觉。聊天里或书桌上的任意图片、视频点开,是一层暗色遮罩的全屏预览,滚轮缩放、拖拽平移,左右箭头在同会话或同目录的相邻媒体间切换。关键不在功能本身(看图软件都有),在于动效的节奏:遮罩淡入不是生硬的出现,缩放有缓动,切换有过渡。这些不是“炫技”,是让每一次操作都感觉“被好好对待了”。
如果把同类产品拉出来对比就很明显:不少 CLI-first 的 Agent 功能强大到飞起,但界面就是几行纯文本配 ANSI 颜色码。不是它们不想好看,而是它们的目标用户不在乎——开发者要的是“快”,不是“舒服”。OpenHanako 选了另一条路:让非开发者也有打开它的欲望。
一个容易被忽略的洞察
用户每天面对的不是一个模型、一组 API,而是一个界面。AI 本身没有形状,界面就是它的身体。OpenHanako 的设计语言不是在“美化一个工具”,而是在给 AI 一具让人愿意亲近的身体。
选色、排版、间距、动效——这些在编码优先的项目里往往被压缩到最后一个 sprint 随便糊一下。但 OpenHanako 的 README 截图一放出来就能看出,作者对视觉是有要求的。这种要求不是设计师那种“像素级对齐”的执念,而是一种更简单的东西:希望你打开这个软件的时候,心情是好的。
十一、局限与诚实的评价
用了这段时间,几个问题需要坦诚说:
- Windows 仍在 Beta:偶发的 UI 卡顿和内存占用偏高(常驻约 1GB+),小内存机器需要谨慎
- 模型依赖:记忆编译和技能沉淀的质量高度依赖底层模型,用弱模型效果会打折
- 学习成本:虽然比 CLI Agent 友好很多,但 SOUL.md / 技能 / 频道 / 桥接等概念仍然需要时间理解
- 社区生态:相比 Hermes 的 30K stars,OpenHanako 的社区还在早期(约 2500 stars),插件和技能资源相对少
- 主动性的边界:Agent 的“主动关心”目前还比较机械,距离真正的“懂你”还有距离
十二、谁适合用
适合:
- 希望 AI 助手有“人格感”、不只是冷冰冰的工具
- 日常办公场景多,需要跨平台(电脑 + 手机)连续对话
- 想要一个能记住你说过什么、主动提醒你的长期伙伴
- 对开源和数据隐私有要求
不太适合:
- 只需要“问一句答一句”的轻度用户
- 追求极致响应速度和最低资源占用
- 没有耐心做初期配置和调校
十三、写在最后
OpenHanako 的作者在 README 里有一句话打动了我:“弥合绝大多数人和 AI Agent 之间的缝隙。”
这句话点出了一个被忽略的事实:当前 AI Agent 生态的最大鸿沟,不是技术能力,而是使用门槛。CLI-first 的 Agent 再强大,对不会写代码的人来说就是不存在的。OpenHanako 试图用 GUI、人格、记忆、多平台这些“非技术特性”,把 Agent 的能力翻译成所有人都能用的语言。
它目前还不完美——Beta 阶段的 Windows 版、还在成长的社区、需要调校的主动性——但它走的这条路,指向了一个值得期待的方向:AI 助手不只是效率工具,还可以是一个有温度的存在。
相关链接:
- 项目地址:github.com/liliMozi/openhanako
- 官网:openhanako.com
- 下载:Releases
- 插件开发指南:PLUGINS.md
- 贡献指南:CONTRIBUTING.md
- 作者的抖音主页:liliMozi
它的作者 liliMozi 是一位中国开发者,一人全职维护这个项目——从代码到设计到文档,一个人扛下了整个产品。这篇文章基于实际使用体验,聊聊这个项目的定位、核心机制、和同类产品的差异。
]]>